Clickhouse RunningAccumulate()로 누적값 구하기
2021. 6. 30.Career/Data
MySQL이나 PostgreSQL이라면 Partition by나 OVER등을 사용해서 누적값을 쉽게 구했을 지 모르겠지만 한동안 Clickhouse에서는 쉽게 누적값을 구하는 방법을 몰라서 그냥 python pandas를 이용해서 누적값을 구한 테이블을 가공하여 가공 테이블을 사용하는 방식으로 누적 그래프 등을 그렸다. 하지만 오늘 RunningAccumulate()라는 함수로 쉽게 누적 값을 구할 수 있는 방법을 알게 되었다. 함수 이름은 누가봐도 누적값 계산인데 왜 그 동안 몰랐을까? 사용하는 방법은 아주 간단하다.
일단 내가 가지고 있는 데이터는 이러하다. 각 월별로 몰 수가 카운팅 된 데이터 인데, 이 데이터를 이용해서 누적 값을 구해보려고 한다.
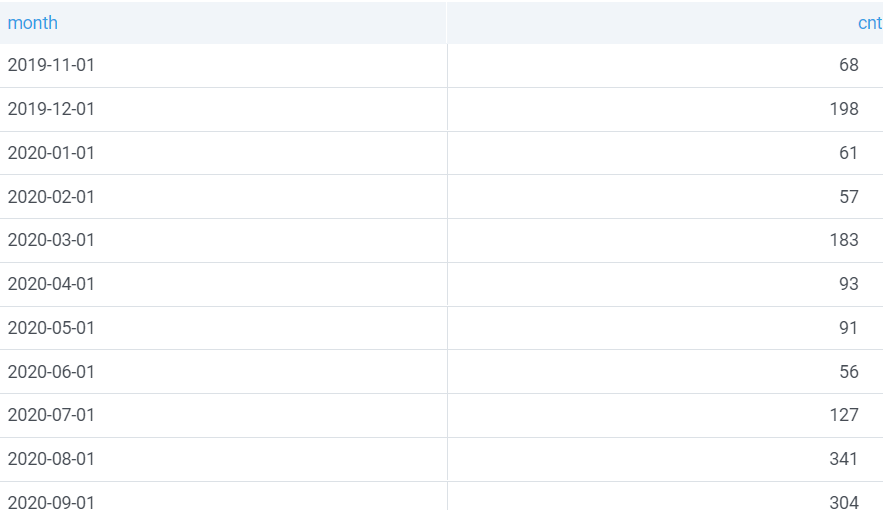
이 데이터를 runningAccumulate() 함수를 이용해서 누적 값을 구하기 위해서는 두 가지를 주의하여 데이터를 전처리 해주어야 한다.
1. 누적값을 구할 순서대로 정렬이 되어 있어야 한다는 것
- 나는 월 증분에 따른 누적값을 구할 것이기에 month가 작은 순으로 오름차순하였다. 이렇게 정렬한 데이터를 서브쿼리로 하여 메인 쿼리에서 runningAccumulate()를 사용하면 된다.
2. 그리고 countState() 함수를 이해할 것
- -State()는 괄호안에 들어가는 대상을 집계할 상태로 만들어주는 함수이다. 예를 들어, 지금 처럼 몰 수를 카운팅 한 다음에 누적 값을 구하는 경우에 ' 카운팅 한 후 누적 ' 이라는 여러 번의 집계를 하게 되는 데 클릭하우스는 이 -State 함수로 이 값을 집계할거야. 라고만 선정해두고 실제로는 마지막 집계 함수를 입력하고 쿼리를 Run할 때 최적화된 방법으로 여러 번의 집계를 해주나보다. 그래서 실제로 count는 먼저 하지 않지만 나는 countState(mall_id)와 같이 이 몰 수를 카운팅 하겠다고 만들어주었다. 참고로 sumState()도 있다. 집계함수 뒤에 -State()를 붙이면 된다고 한다. ( 참고 : https://clickhouse.tech/docs/en/sql-reference/data-types/aggregatefunction/#data-type-aggregatefunction )

이렇게 월을 기준으로 오름차순 정렬한 데이터를 서브 쿼리로 하여 countState에 두었던 값을 runningAccumulate() 함수로 누적 값을 와르르 구하니 아래와 같이 누적 값 데이터 셋이 생성 되었다.

정말 편리한 Clickhouse의 세계 (o^^o) 이제껏 pandas로 누적값을 구해왔던 시간들이 조금 아깝지만 그 나름의 배울점이 있다 생각하면서 오늘의 공부 끄읕-!
'Career > Data' 카테고리의 다른 글
| matplotlib로 그래프 그려 성장 추이 찾기 (0) | 2021.09.02 |
|---|---|
| 마지막 접속 일자 데이터 체크 하기 (0) | 2021.07.26 |
| Clickhouse Limit by 구문으로 최신 데이터 불러 오기 (0) | 2021.07.05 |
| Clickhouse Query로 YoY(year-over-year) 구하기 (0) | 2021.04.18 |
| 왜 Clickhouse 인가? (0) | 2020.12.16 |
Career/Data의 다른 글




